
Progetto Facebook Rosetta

Progetto Facebook Rosetta: l’algoritmo che individua il testo nelle immagini e nei video
Facebook sta testando quali sono i potenziali dell’intelligenza artificiale nell’ambito del riconoscimento dei testi nelle foto e nei video.
Questo avviene con il Progetto Facebook Rosetta
Facebook dichiara, attraverso il suo blog, che comprendere il testo che appare nelle immagini è importante per migliorare le esperienze degli utenti, come una ricerca di foto più rilevante o l’integrazione del testo in screen reader, che rendono Facebook più accessibile per i non vedenti. Comprendere il testo nelle immagini insieme al contesto in cui appare aiuta anche i sistemi Facebook ad identificare proattivamente contenuti inappropriati o dannosi e a mantenere la community al sicuro.
Una vera e propria sfida: non solo rilevare il testo ma comprenderlo associandolo all’immagine
Un numero significativo di foto condivise su Facebook e Instagram contengono testo in varie forme. Potrebbe essere sovrapposto a un’immagine in un meme o presente in una foto di un negozio, un segnale stradale o un menu del ristorante. Tenendo conto dell’elevato volume di foto condivise ogni giorno su Facebook ed Instagram, il numero di lingue supportate sulla piattaforma globale e le variazioni del testo, il problema della comprensione del testo nelle immagini è molto diverso da quello risolto dal tradizionale carattere ottico sistemi di riconoscimento (OCR), che riconoscono i caratteri ma non comprendono il contesto dell’immagine associata.
Il progetto Facebook Rosetta
Per ottenere questi risultati Facebook ha sviluppato ed implementato un sistema di apprendimento automatico su larga scala di nome Rosetta. Estrae il testo da oltre un miliardo di immagini e fotogrammi video pubblici di Facebook e Instagram (in un’ampia varietà di lingue), quotidianamente e in tempo reale e lo inserisce in un modello di riconoscimento del testo che è stato addestrato attraverso classificatori per comprendere il contesto in cui il testo e l’immagine sono interconnessi.

Come avviene l’analisi delle immagini di Rosetta? – Facebook Rosetta
L’analisi del testo su un’immagine avviene in due fasi indipendenti: rilevamento e riconoscimento. Nel primo passaggio, Rosetta rileva regioni rettangolari che potenzialmente contengono testo. Nella seconda fase, procede con il riconoscimento del testo, dove, per ognuna delle regioni rilevate, utilizza una rete neurale convoluzionale (CNN) per riconoscere e analizzare la parola nella regione.
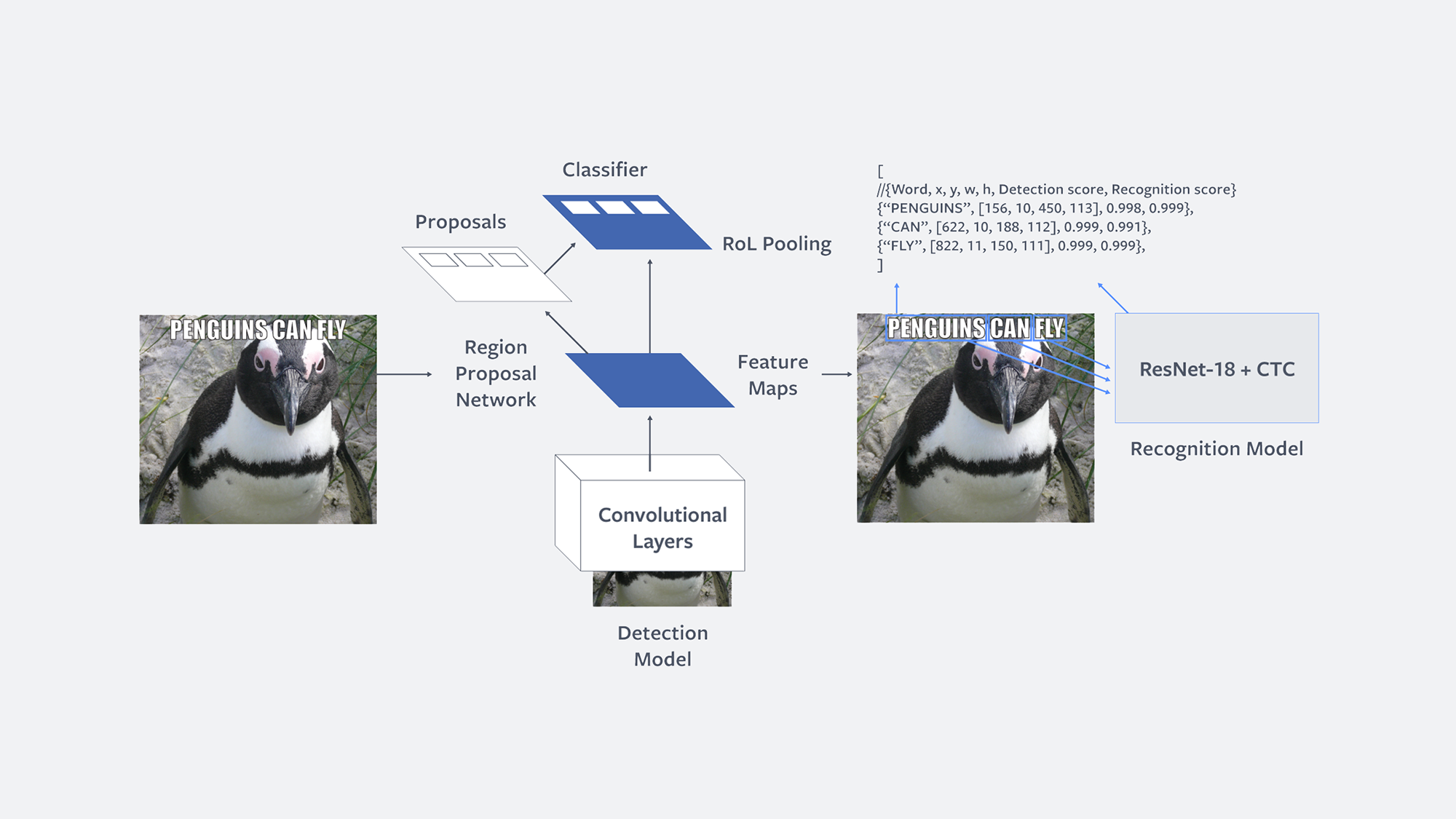
Non solo lettura ma comprensione ed apprendimento – Facebook Rosetta
Rosetta parte da comprendere parole brevi, con un massimo di cinque caratteri. Una volta che tutte le parole di cinque o meno caratteri vengono compresse, il sistema va a scalare con parole di sei o meno caratteri, poi sette o meno, ecc.

Rosetta è stata ampiamente adottata da vari prodotti e team all’interno di Facebook ed Instagram. Il testo estratto da immagini viene utilizzato come caratteristica in vari modelli di apprendimento automatico a monte come quelli per migliorare la pertinenza e la qualità della ricerca di foto, identificare automaticamente il contenuto che viola la nostra politica di incitamento alla parola sulla piattaforma in varie lingue e migliorare la precisione di classificazione delle foto in News Feed per rendere più personalizzato il contenuto.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}